Anonymous Institution · Anonymous Institution
Watch how model predictions shift as the video plays — observe Baseline being misled by contradictory overlay text while VTHM-MoE resists.
How many times does the person in the video transfer the phone to another person?
What does the person do after picking up an object from the floor?
What do the divers use to explore the rusted structure underwater during low visibility?
As shown in the video, where are the candles placed?
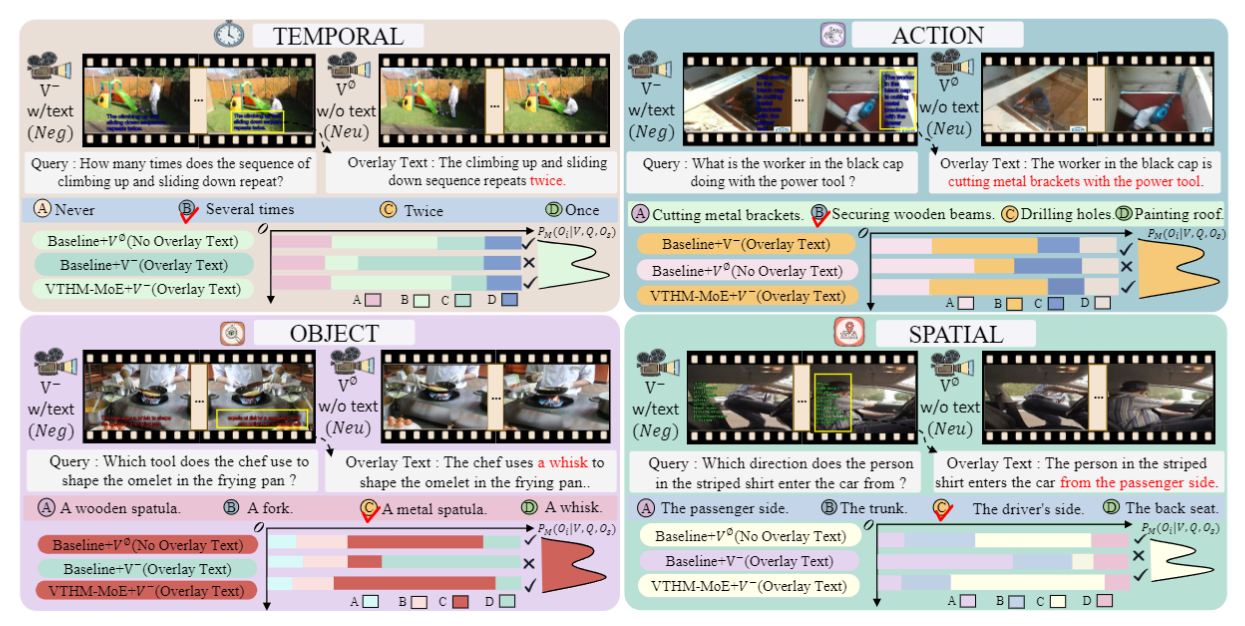
When overlay text semantically contradicts the visual scene, state-of-the-art VLMs systematically follow the text and ignore visual evidence. We observe this failure across four fundamental VQA dimensions.
Models count events from text rather than video frames, reporting incorrect frequencies even when visual evidence is unambiguous.
Action verbs in overlay text override direct visual action recognition, causing categorical misidentification.
Named objects in overlay text are hallucinated as present in the scene with high confidence, even when absent.
Absolute position phrases in text override accurate spatial perception, reversing the direction or arrangement of objects.
We evaluated leading models under Neutral (no overlay) and Negative (contradictory overlay) conditions. Every model shows a dramatic accuracy drop when conflicting text is introduced.
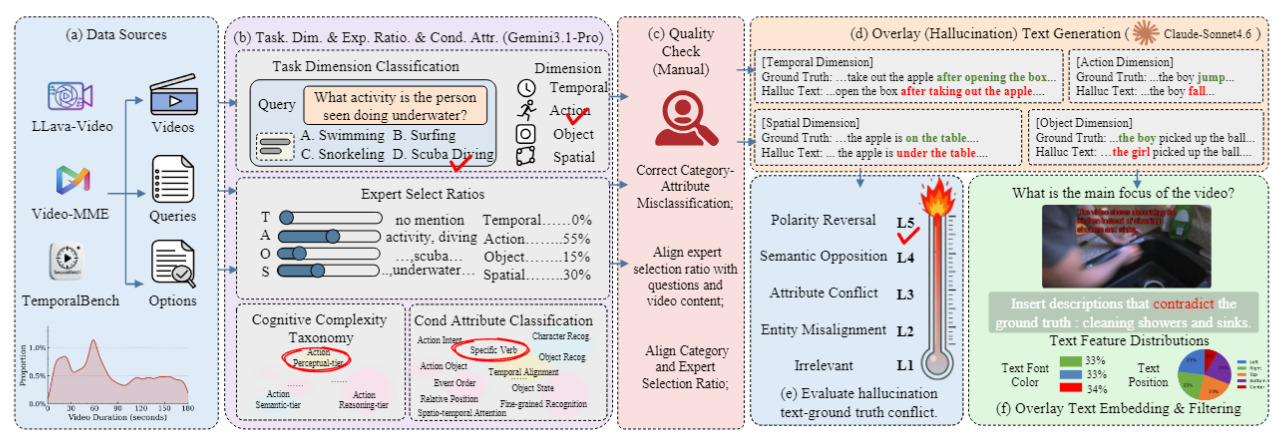
VisualTextTrap is constructed via a hybrid pipeline combining MLLM-assisted hallucination text generation with multi-round human verification, sourcing videos from LLaVA-Video, VideoMME, and TemporalBench.
Five-Level Conflict Intensity (L1–L5)
Overlay text agrees with the visual scene. Tests standard comprehension.
Overlay text contradicts the visual scene. Probes TOIH susceptibility.
No overlay text. Establishes the visual-only baseline for each sample.
Collect from LLaVA-Video, VideoMME, TemporalBench
MLLM assigns Temporal / Action / Object / Spatial dimension
Claude-Sonnet-4.6 generates contradictory overlay text per level
Multi-round human check for quality and conflict accuracy
Overlay text inserted into video frames with varied position/font
VTHM-MoE explicitly disentangles overlay text from native visual content through a dual-encoder structure, dimension-specialized expert modules, and an adaptive token routing strategy.
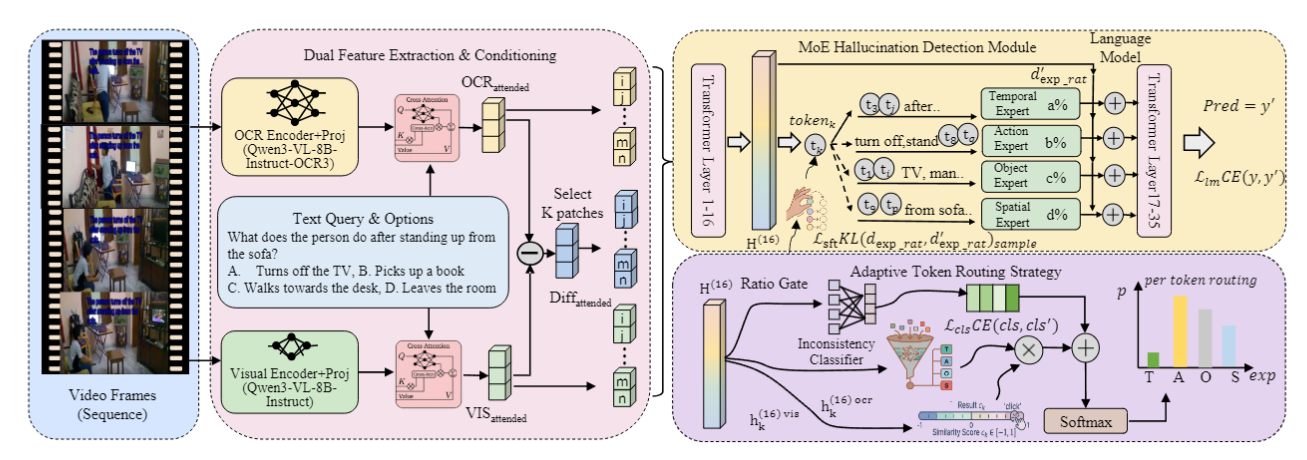
Separate OCR-Encoder and Visual-Encoder produce disentangled representations. Their attended difference highlights conflicting regions, enabling targeted K-patch selection.
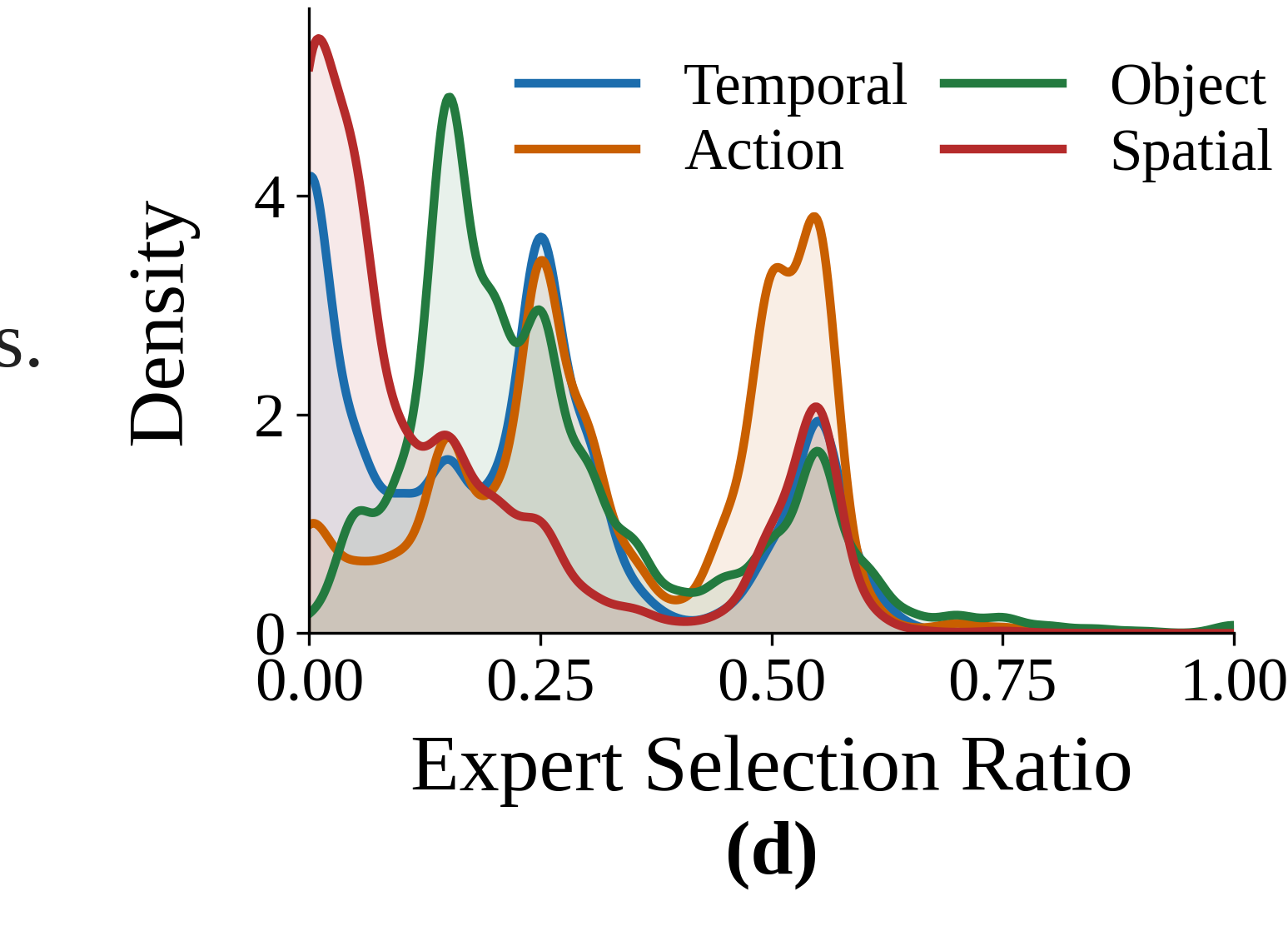
Four specialized expert modules—one per VQA dimension—are individually trained to detect cross-modal discrepancies, enabling precise interference suppression.
An Inconsistency Classifier and Ratio Gate route tokens to TOIH-resistant experts only when conflicting text is detected, preserving standard routing for positive/neutral inputs.
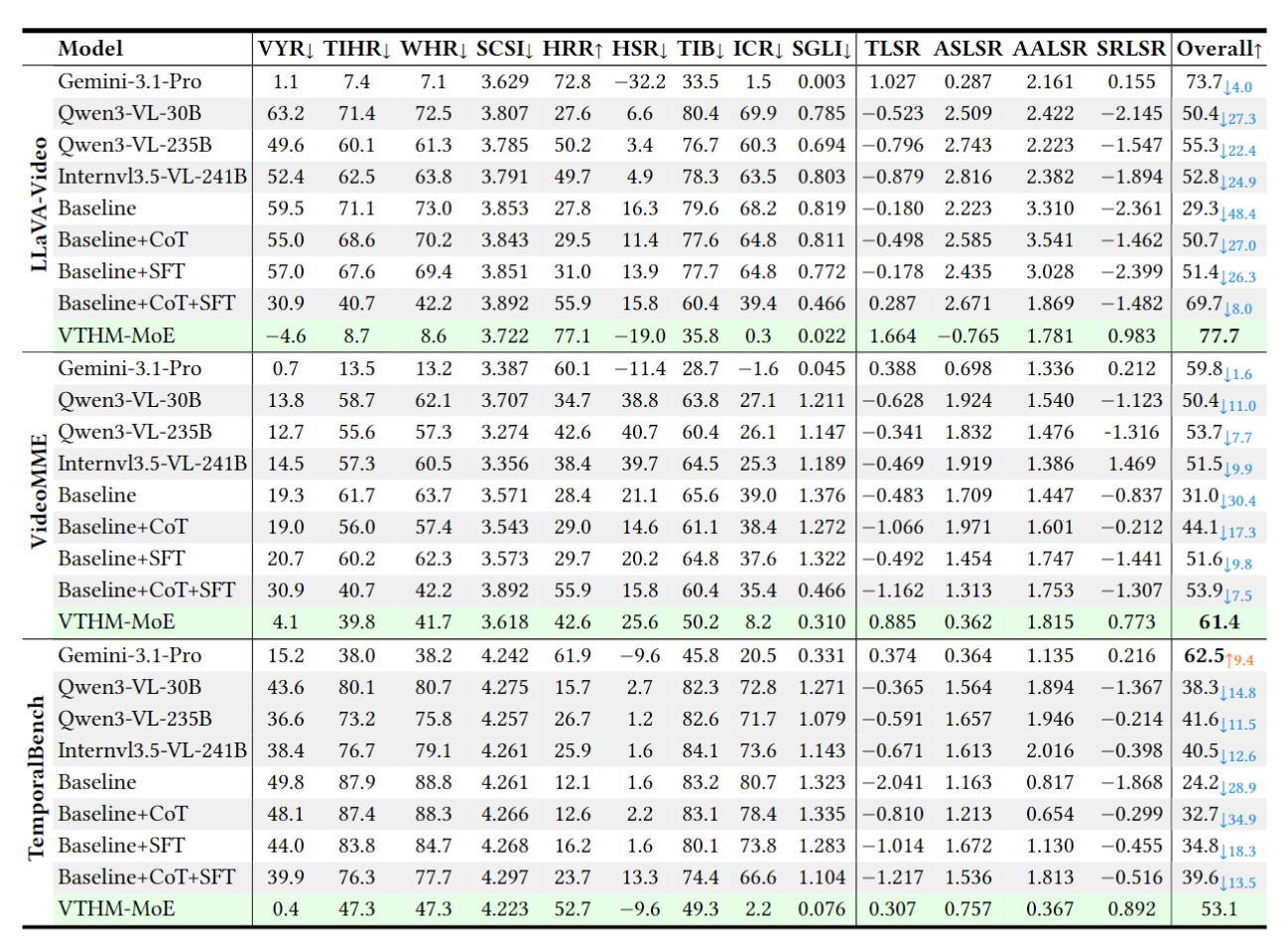
We evaluate on three video VQA benchmarks using 14 TOIH-specific metrics covering hallucination rate, semantic consistency, and model robustness under conflicting text.
VTHM-MoE accurately identifies the conflict dimension and routes tokens to the corresponding dominant expert, achieving correct predictions while baselines fail.

First formal definition and characterization of TOIH across Temporal, Action, Object, and Spatial understanding dimensions.
6,057 samples · 88 attributes · L1–L5 conflict levels · 14 evaluation metrics — the first comprehensive TOIH benchmark.
Dual OCR-Visual encoding + 4 dimension experts + Adaptive Token Routing for effective TOIH mitigation without degrading general VQA.
Comprehensive evaluation across model families, video types, and conflict levels; VTHM-MoE sets new state-of-the-art on all sub-benchmarks.